What is Big Data?
Big Data represents enormous & complex data points or datasets, particularly those taken up from new data sources. These datasets are so huge in size that traditional technologies of data processing just cannot handle them. However, these huge volumes of data can be utilized to address business challenges that individuals were previously unable to address.
If the data follows the properties, we can refer to the data as Big Data.
- Volume (amount of data): The amount of data created by organizations or individuals is referred to as volume. Big Data arrives in ever-increasing volumes.
- Velocity (speed of data in and out): Velocity describes the frequency at which data is generated, captured, and shared. Big Data comes with extremely high Velocity.
- Variety (diversity of data sources and types): Big Data encompasses far more than rows and columns. It refers to unstructured text, video, and audio, etc that may have a significant influence on business choices if correctly analyzed in a timely manner. Big Data comes in a wide variety of file formats and types.
What is ETL?
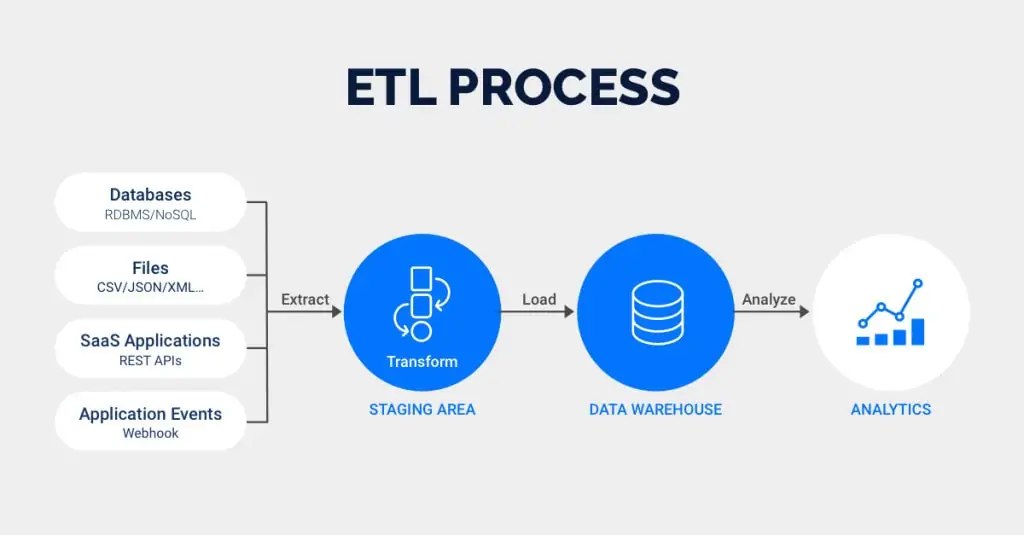
ETL is the short form of “Extract, Transform, Load,” the three processes that, when combined, allow organizations to move and consolidate data from a single database, several databases, or other sources into a single, unified repository with appropriately formatted data—typically a Data Warehouse. Organizations leverage ETL Tools to set up and achieve this process of Data Integration. So, if you’ve ever had a thought “What is ETL Tool?”, here’s your answer! It helps data analysis to produce actionable business information by effectively preparing data for analysis and business intelligence procedures. This unified data repository simplifies access to data for analysis and subsequent processing. It also serves as a Single Source of Truth (SSOT) for all enterprise data, ensuring that it is consistent and up to date.
Processes in ETL
There are 3 distinct processes in extract, transform, load, which are performed by ETL Tools. These are:
- Extraction: In this process, Raw data is pulled from one or more siloed data sources. Data could be pulled from transactional applications like HubSpot, ERP software like SAP, or Internet of Things (IoT) sensors, etc. Data extracted can be in a variety of file formats, including Relational Databases, XML, JSON, multimedia files, and so on.
- Transformation: In this process, data is updated or processed to meet the demands of a company and the specifications of its data storage system. Standardizing (converting all data types to a single format), cleansing (resolving discrepancies and inaccuracies), mapping (consolidating data elements from multiple models), augmenting (bringing in data from external sources), and other processes can all be included in this process.
- Loading: In this process, Data is delivered and secured for sharing, making business-ready data available to users and departments within the organization and sometimes outside of the organization as well. This procedure may entail overwriting the destination’s existing data. The data is primarily put into a centralized repository for the whole organization.
What is the traditional ETL Process?
Traditionally, ETL needed specialized IT personnel who could develop and manage on-premise databases and data pipelines. The procedure was time-consuming since it relied on extensive batch processing sessions. IT required to know the target schema at the time of loading in order to transform the data while it was in route to match the schema. Traditional ETL technology was particularly difficult to scale since it tended to compromise raw data granularity for performance as data volumes increased.
Challenges of Traditional ETL Processes
The challenges associated with Traditional ETL Processes were:
1. Time
Traditional ETL tools necessitate a lot of manual effort. Hence, these takes a more prolonged time to build the jobs, metadata import for multiple stages like data mart, edw, ods, etc.
2. Errors
Traditional ETL platforms are also prone to errors. If one stage fails to process, subsequent stages’ tasks cannot perform, resulting in bottlenecks.
3. Flexibility
Traditional ETL solutions copied just the sections of the data that they thought significant, resulting in gaps and data integrity issues.
4. Transformation
Legacy technologies depended primarily on strict schemas and were incapable of handling discrete and unstructured data formats. Due to a lack of appropriate tools, analysts were obliged to omit some parameters from their data models.
5. Integration
Most legacy systems have high hardware needs and fail to interface with existing infrastructure, adding to your organization’s costs.
6. Limited Processing
Traditional ETL solutions are only capable of processing relational data. They are incapable of processing unstructured and semi-structured data formats, resulting in data loss and integrity issues.
7. Efforts
Traditional ETL platforms need manual efforts to construct and manage the data pipeline.
8. Inconsistence
Traditional ETL technologies are also inconsistent, as they do not provide data replication or schema propagation. As a result, any changes from the source need to be manually transferred into the data pipeline.
9. Scalability
Traditional ETL systems struggled to handle a sudden increase in data flows. The tools performed poorly, resulting in excessively long and sluggish analytical cycles.
10. Visualization
With older systems, gaining a full picture of your data was a significant issue. They do not provide real-time access to specific data points, resulting in outdated and inaccurate reports.
11. Cost
Traditional ETL solutions have relatively expensive operational, license, and maintenance costs, which add to the existing costs of the ETL procedures.
12. Lack of Vision
Frequently, tools are purchased with the current data demands of the company in mind. Traditional ETL technologies are incapable of supporting the organization’s future data demands and data types.
Traditional ETL Fell Short
Traditionally, a small team of data scientists could manage ETL operations for a limited number of data sources.
However, when data Volume and Velocity rose, the systems and procedures broke down. To clarify, rising volumes of data in a typical on-premises data warehouse need high-speed disc capacity to store huge data sets, fast processors to do computations, and rapid memory to effectively perform data operations. Most IT departments could not afford to buy and employ those computational resources just for ETL projects. As a result, they had to reduce the impact on other systems by batch processing data only when system traffic was low. As a result, ETL was sluggish and expensive, and BI users were unable to undertake real-time analysis or even ETL outside of scheduled batches.
Traditional data transformation and ETL solutions are intended to deal with relational databases and are not suitable for unstructured data. As a result, firms that need to incorporate unstructured data into their business process decision-making have had to rely on a large amount of manual coding to accomplish the essential data integration. Most businesses chalked up these lengthy and complex processes to the expense of participating in the Big Data Revolution. However, hand-coded data integration processes are especially challenging.
These settings shift the load and cost of data maintenance onto the engineering team of the firm. Adding capacity to meet growing demand may result in more expenses (power consumption, hardware, and staff overhead), as well as a higher chance of downtime or service disruptions.
Changes in the technology stack and the introduction of Big Data have made the Traditional ETL Tools brittle and unable to adapt to a fast-changing business environment
And, as the Volume and Variety of data sources grows, so do the requirements for tracking and querying them. As a result, businesses are increasingly migrating their data to cloud data warehouses. Traditional ETL was never designed for the cloud, and it is incapable of scaling to keep up. As a result of the bottlenecks, reports and analytics are delayed, making it difficult to obtain timely data for informed decision making. Hence, anyone who still leverages the traditional way for ETL in the Big Data era can often face their risk of missing out on opportunities and losing revenues.
Cloud-Based ETL to the Rescue
In today’s business environment, data intake must be real-time and provide users with the ability to conduct queries and observe the current state at any moment. And, as businesses shift an increasing number of their applications and workloads to the cloud, they’ll be confronted with exponentially more data i.e, Big Data – in greater data sets, different formats, and from a variety of sources and streams. Thus, their ETL tools must be able to readily manage this mass of data effortlessly. This is where Cloud-based ETL tools come to the rescue in the era of Big Data.
Conclusion
This blog introduces the impact of Traditional ETL in Big Data in detail. It also gives a quick overview of Big Data and ETL Technologies.